Main Entities#
Flowman is a data build tool which uses a declarative syntax to specify, what needs to be built. The main difference
to classical build tools like make, maven is that Flowman builds data instead of applications or libraries.
Flowman borrows many features from classical build tools, like support for build phases, automatic
dependency detection, clean console output, and more.
But how can we instruct Flowman to build data? The input and output data is specified in declarative YAML files together with all transformations applied along the way from reading to writing data. At the core of these YAML files are the following entity types
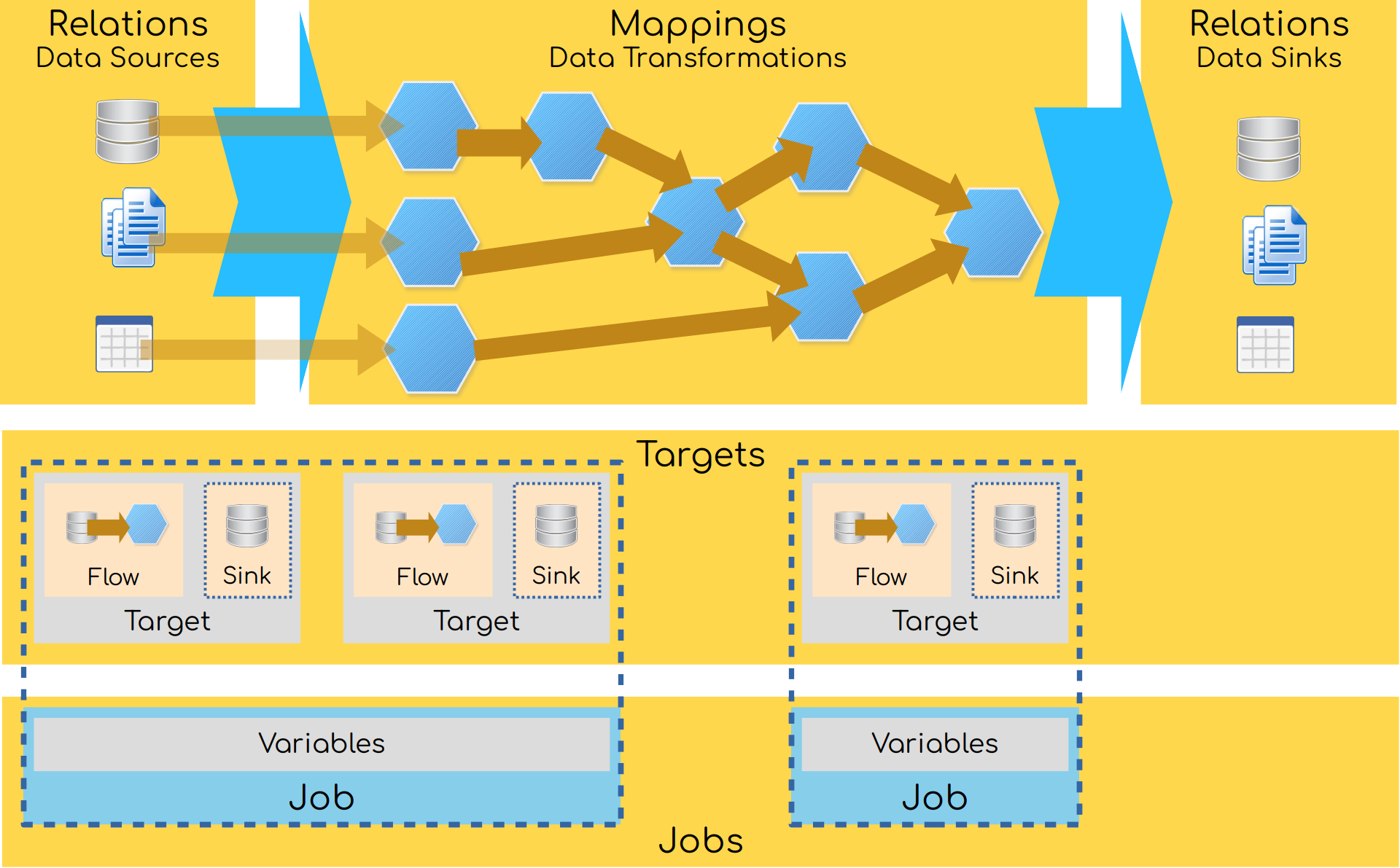
Relations#
Relations specify physical manifestations of data in external systems. A relation may refer to any data source (or sink) like a table or view in a MySQL database, a table in Hive or files on some distributed file system like HDFS or files stored in object store like S3.
A relation can serve both as a data source or a data sink, or as both (this is when automatic dependency management comes into play, which is required to determine the correct build order). Each relation typically has some important properties like its schema (i.e. the columns including name and type), its location (be it a directory in a shared file system or a URL to connect to). Of course, the available properties depend on the specific kind of relation.
Examples#
For example a table in Hive can be specified as follows:
relations:
parquet_relation:
kind: hiveTable
database: default
table: financial_transactions
# Specify the physical location where the data files should be stored at. If you leave this out, the Hive
# default location will be used
location: /warehouse/default/financial_transactions
# Specify the file format to use
format: parquet
# Add partition column
partitions:
- name: business_date
type: string
# Specify a schema, which is mandatory for write operations
schema:
kind: inline
fields:
- name: id
type: string
- name: amount
type: double
And a table in a MySQL database can be specified as:
relations:
frontend_users:
kind: jdbcTable
# Specify the name of the connection to use
connection:
kind: jdbc
driver: "com.mysql.cj.jdbc.Driver"
url: "jdbc:mysql://mysql-crm.acme.com/crm_main"
username: "flowman"
password: "super_secret"
# Specify the table
table: "users"
Or you can easily access files in S3 via:
relations:
csv_export:
kind: file
# Specify the file format to use
format: "csv"
# Specify the base directory where all data is stored. This location does not include the partition pattern
location: "s3://acme.com/export/weather/csv"
# Set format specific options
options:
delimiter: ","
quote: "\""
escape: "\\"
header: "true"
compression: "gzip"
# Specify an optional schema here. It is always recommended to explicitly specify a schema for every relation
# and not just let data flow from a mapping into a target.
schema:
kind: inline
fields:
- name: country
type: STRING
- name: min_wind_speed
type: FLOAT
- name: max_wind_speed
type: FLOAT
Mappings#
The next very important entity of Flowman is the mapping category which describes data transformation (and in addition as a special but very important kind, reading data). Mappings can use the result of other mappings as their input and thereby build a complex flow of data transformations. Internally all these transformations are executed using Apache Spark.
There are all kinds of mappings available, like simple filter mappings, aggregate mappings and very powerful generic SQL mappings. Again, each mapping is described using a specific set of properties depending on the selected kind.
Examples#
The example below shows how to access a relation called facts_table (which is not shown here). It will read a
single partition of data, which is commonly done for incremental processing only newly arrived data.
mappings:
facts_all:
kind: relation
relation: facts_table
partitions:
year:
start: $start_year
end: $end_year
The following example is a simple filter mapping, which is equivalent to a WHERE clause in traditional SQL. It applies
the filter to the output of the incoming facts_all mapping (not shown).
mappings:
facts_special:
kind: filter
input: facts_all
condition: "special_flag = TRUE"
You can also perform arbitrary SQL queries (in Spark SQL) by using the sql mapping:
mappings:
people_union:
kind: sql
sql: "
SELECT
first_name,
last_name
FROM
people_internal
UNION ALL
SELECT
first_name,
last_name
FROM
people_external
"
Targets#
Now we have the two entity types mapping and relation, and we already saw how we can read from a relation using
the relation mapping. But how can we store the result of a flow of transformations back into some relation? This
is where build targets come into play. They kind of connect the output of a mapping with a relation and tell Flowman
to write the results of a mapping into a relation. These targets are the entities which will be built by Flowman and
which support a lifecycle starting from creating a relation, migrating it to the newest schema, filling with data,
verifying it etc.
Again Flowman provides many types of build targets, but the most important one is the relation build target
Examples#
The following example writes the output of the mapping stations_mapping into a relation called stations_table.
Again the example will only write into a single partition for incrementally processing only new data.
targets:
stations:
kind: relation
mapping: stations_mapping
relation: stations_table
partition:
processing_date: "${processing_date}"
Jobs#
While targets would contain all the information for building the data, Flowman uses an additional entity called job which simply bundles multiple targets, such that they are built together. The idea is that while your project may contain many targets, you might want to group them together, such that only specific targets are built together.
And this is done via a job in Flowman, which mainly contains a list of targets to be built. Additionally, a job allows specifying build parameters, which need to be provided on the command line. A typical example would be a date which selects only a subset of the available data for processing.
Examples#
The following example defines a job called main with two build targets stations and weather. Moreover, the job
defines a mandatory parameter called processing_date, which can be referenced as a variable in all entities.
jobs:
main:
description: "Processes all outputs"
parameters:
- name: processing_date
type: string
description: "Specifies the date in yyyy-MM-dd for which the job will be run"
environment:
- start_ts=$processing_date
- end_ts=$Date.parse($processing_date).plusDays(1)
targets:
- stations
- weather
Additional entities#
While these four types (relations, mappings, targets and jobs) form the basis of every Flowman project, there are some additional entities like tests, connections and more. You find an overview of all entity types in the project specification documentation
Lifecycle#
Flowman sees data as artifacts with a common lifecycle, from creation until deletion. The lifecycle itself consists of multiple different build phases, each of them representing one stage of the whole lifecycle. Each target supports at least one of these build phases, which means that the target is performing some action during that phase. The specific phases depend on the target type. Read on about lifecycles and phases for more detailed information.