Flowman#
![]()
![]()
What is Flowman#
Flowman is a Spark based data build tool that simplifies the act of writing data transformation application. Flowman can be seen as an ETL tool, with a strong focus on transformation and schema management.
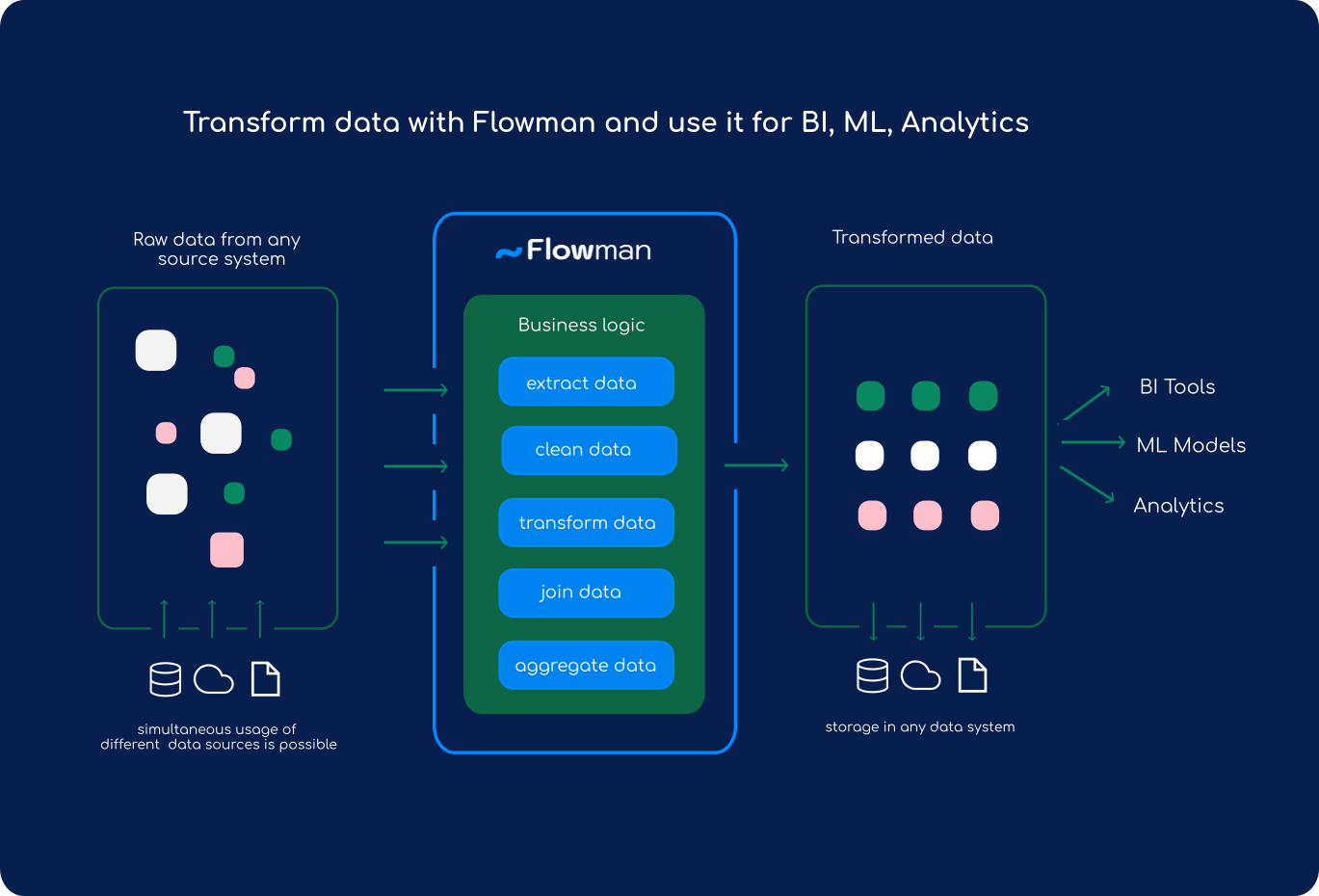
The main idea is that developers define all input/output tables and the whole transformation logic in purely declarative YAML files instead of writing complex Spark jobs in Scala or Python. The main advantage of this approach is that many technical details of a correct and robust implementation are encapsulated, and the user can concentrate on the data transformations themselves.
In addition to writing and executing data transformations, Flowman can also be used for managing physical data models, i.e. Hive tables but also JDBC tables. Flowman will create such tables from a specification with the correct schema, and Flowman also provides mechanisms to automatically migrate these tables when the schema changes due to updated transformation logic (i.e. new columns are added, data types are changed, etc.).
This helps to keep all aspects (like transformations and schema information) in a single place managed by a single application.
Use Cases#
Flowman suits well to the requirements of a modern Big Data stack serving multiple different purposes like reporting, analytics, ML and more. Building on Sparks ability to integrate different data sources, Flowman will serve as the central place in your value chain for data preparations for the next steps.
Flowman supports many different execution environments from trivial non-distributed Docker, over managed Spark clusters like AWS EMR and Azure Synapse to classical on premise Hadoop clusters like Cloudera.
Notable Features#
Declarative syntax in YAML files
Full lifecycle management of data models (create, migrate and destroy Hive tables, JDBC tables or file based storage)
Flexible expression language
Jobs for managing build targets (like copying files or uploading data via SFTP)
Automatic dependency analysis to build targets in the correct order
Powerful yet simple command line tool for batch execution
Powerful Command line tool for interactive data flow analysis
History server that provides an overview of past jobs and targets including lineage
Metric system with the ability to publish these to servers like Prometheus
Extendable via Plugins
Where to go from here#
Quick Start & Tutorial#
A small quick start guide will lead you through a simple example.
Quick Start Guide
Core Concepts#
In order to successfully implement your projects with Flowman, you need to get a basic understanding of Flowman’s core concepts and abstractions.
Tutorial#
After you have finished the introduction, you may want to proceed with the Flowman tutorial to get more in-depth knowledge step by step.
CLI Documentation#
Flowman provides a command line utility (CLI) for running flows. Details are described in the following sections:
Flowman Executor: Documentation of the Flowman Executor CLI
Flowman Shell: Documentation of the Flowman Shell CLI
Flowman Server: Documentation of the Flowman Server CLI
Workflow#
Flowman provides simple but powerful command line tools for executing your projects. This provides a great flexibility for defining your perfect workflow from development to production deployment. But this flexibility makes it more difficult to get started. Luckily Flowman also provides some guidance for setting up your projects and for defining a streamlined development workflow.
Development & Deployment Workflow: How to implement an efficient development workflow with Flowman
Specification Documentation#
So-called specifications describe the logical data flow, data sources and more. A full specification contains multiple entities like mappings, data models and jobs to be executed. More detail on all these items is described in the following sections:
Specification Overview: An introduction for writing new flows
Mappings: Documentation of available data transformations
Relations: Documentation of available data sources and sinks
Targets: Documentation of available build targets
Schema: Documentation of available schema descriptions
Jobs: Documentation of creating jobs and building targets
Testing & Documenting#
Testing How to implement tests in Flowman
Documenting How to create detailed documentation of your Flowman project
Installation & Configuration#
Flowman Installation: Installation guide for local installation
Running in Docker: How to run Flowman in Docker
Configuration: Configuration settings
Cookbooks#
Cookbooks contain some “how-to”s for frequent issues, like working with Kerberos authentication, integrating automatic Impala catalog updates or overriding JARs and much more.
Connectors & Plugins#
Flowman also provides optional plugins which extend functionality. You can find an overview of all available plugins